
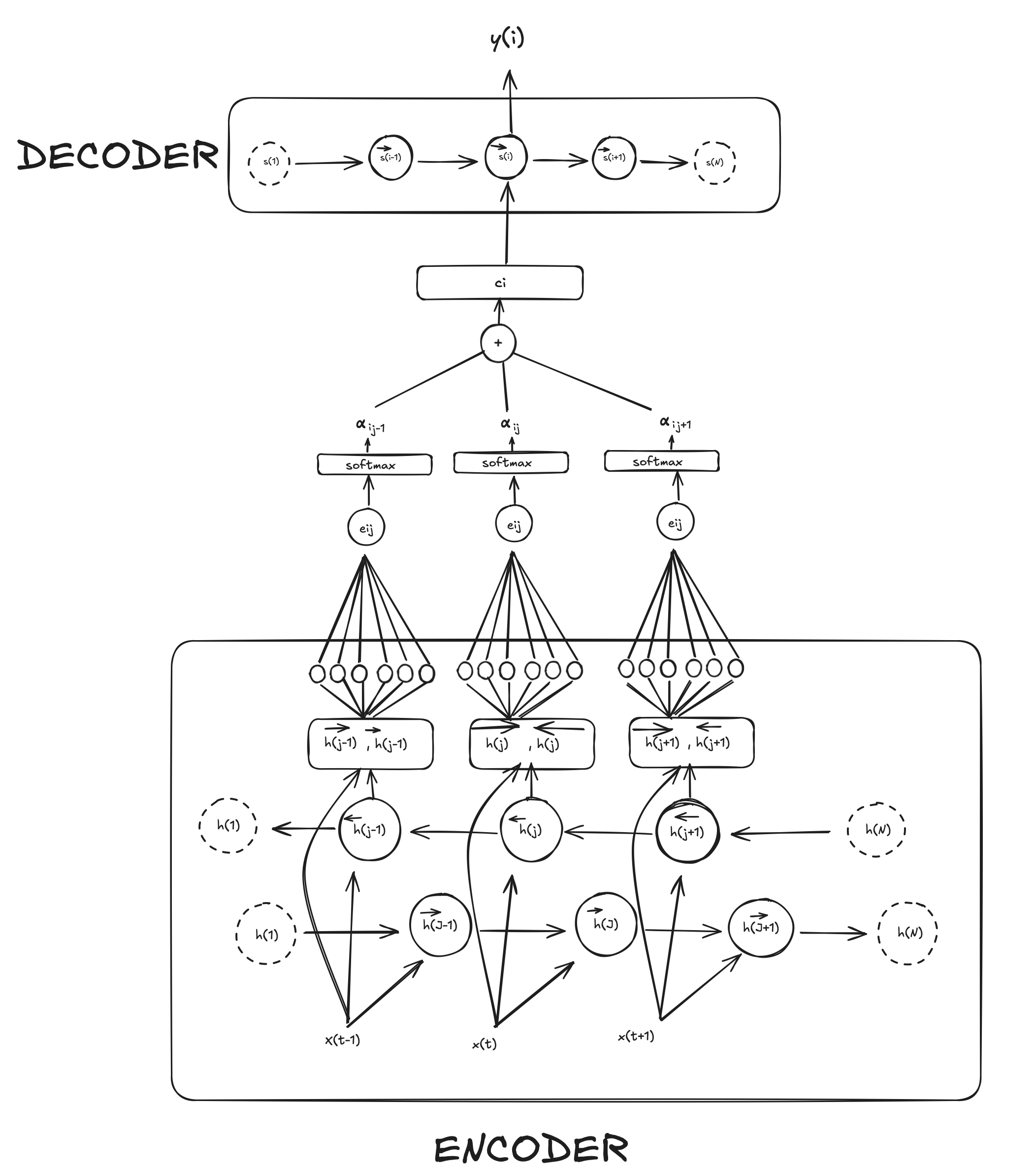
Laplacian Positional Encoding
Published:
Laplacian Positional Encoding
The graph Laplacian is a matrix representation of a graph. For an undirected graph, it’s defined as $L = D - A$, where $D$ is the degree matrix and $A$ is the adjacency matrix.
Laplacian Eigenvectors and Eigenvalues: Relevance to Graph Representation
In graph theory, Laplacian eigenvectors and eigenvalues are derived from the graph Laplacian matrix, a matrix representation that encapsulates the connectivity or structure of a graph. The importance of these eigenvectors and eigenvalues lies in their ability to provide meaningful geometric and topological insights about the graph, allowing us to embed or map a graph into Euclidean space, like a 2D plane. This embedding, known as Laplacian Positional Encoding, creates a local coordinate system that reflects the structure of the graph while preserving its global features, which is crucial for tasks such as graph layout, graph clustering, or graph-based learning.
1. Graph Laplacian and its Definition
Given a graph $G$ with $n$ nodes, its structure can be described by:
Adjacency Matrix $A$: A matrix $A \in \mathbb{R}^{n \times n}$where $A_{ij} = 1$ if there is an edge between nodes $i$and $j$, and 0 otherwise.
Degree Matrix $D$: A diagonal matrix $D \in \mathbb{R}^{n \times n}$ where each diagonal element $D_{ii}$corresponds to the degree of node $i$(i.e., the number of edges connected to node $i$)
The graph Laplacian matrix $L$ is then defined as:
\[L = D - A\]Alternatively, in its normalized form, the Laplacian can be written as:
\[L = I - D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\]where $I$ is the identity matrix and $D^{-\frac{1}{2}}$ normalizes the degree of each node to mitigate the effect of nodes with high degrees.
Purpose of the Laplacian Matrix
The graph Laplacian captures the difference between the degree of each node and its adjacency connections. It is often used in spectral graph theory because its eigenvectors and eigenvalues (derived through matrix factorization) reveal important properties of the graph’s structure.
2. Eigenvalues and Eigenvectors of the Laplacian Matrix
Eigenvectors and Eigenvalues: When we decompose the Laplacian matrix, we get a set of eigenvectors and corresponding eigenvalues. These eigenvectors capture important structural properties of the graph
Given the Laplacian matrix $L$, we solve for its eigenvalues and eigenvectors using the following matrix equation: $L \mathbf{u}_i = \lambda_i \mathbf{u}_i$ where: $\mathbf{u}_i$are the eigenvectors, and $\lambda_i$are the corresponding eigenvalues.
In essence, eigenvalues represent the extent of variation (or spread) along a direction defined by its corresponding eigenvector. For the Laplacian matrix, eigenvalues and eigenvectors carry important information about the graph:
Eigenvalues $\lambda_1, \lambda_2, …, \lambda_n$: Indicate the “smoothness” or structure of the graph. The smallest eigenvalue (which is always 0) corresponds to the “trivial” eigenvector that doesn’t tell us much about the graph’s structure. The non-trivial smallest eigenvalues provide information about large-scale structure, such as graph connectivity.
Eigenvectors $\mathbf{u}_1, \mathbf{u}_2, …, \mathbf{u}_n$: Provide the directions (in the graph’s node space) that correspond to the graph’s most “smooth” variations in structure. These eigenvectors are particularly useful for embedding the graph in low-dimensional spaces.
Intuition: Why is this important for Euclidean representation?
The smallest non-trivial eigenvectors of the Laplacian matrix encode the smoothest variations in the graph, meaning they capture how close or connected neighboring nodes are. These eigenvectors can thus be interpreted as coordinates that embed the graph into a lower-dimensional Euclidean space (e.g., a 2D plane), such that nodes that are strongly connected (close in terms of graph distance) remain close in this new embedding.
Relationship to 2D layout: The eigenvectors of the Laplacian can be thought of as providing a coordinate system for the graph. The second and third eigenvectors (corresponding to the smallest non-zero eigenvalues) are often used to create 2D layouts of graphs, as they capture the main axes of variation in the graph structure.
From Eigenvectors of the Laplacian to 2D
The eigenvectors of the Laplacian can be thought of as providing a coordinate system for the graph. ==The second and third eigenvectors ==(corresponding to the smallest non-zero eigenvalues) are often used to create 2D layouts of graphs, as they capture the main axes of variation in the graph structure.
Laplacian Positional Encoding: LPE extends this idea by using more than just 2 or 3 eigenvectors. By using $k$ eigenvectors, we’re essentially embedding the graph in a $k$-dimensional space, which can capture more nuanced structural information than just 2D or 3D.
Number of eigenvectors and role of eigenvalues
A graph with n nodes will have $n$ eigenvectors. However, one eigenvalue will always be zero (corresponding to the constant eigenvector), so there are at most $n-1$ non-trivial eigenvectors.
When $k$ > number of available eigenvectors: If $k$ is larger than the number of available non-trivial eigenvectors, you have a few options: - Use all available eigenvectors and pad the rest with zeros. - Use all available eigenvectors and repeat them cyclically. - Reduce $k$ to match the number of available eigenvectors.
Role of eigenvalues: The eigenvalues indicate the importance of each eigenvector in describing the graph structure. Smaller non-zero eigenvalues correspond to more important eigenvectors. That’s why we typically use the $k$ smallest non-trivial eigenvectors.
From LPE to 2D layout: The LPE provides a rich, high-dimensional representation of each node’s position in the graph. The model then learns to map this high-dimensional representation to a 2D layout. This is more powerful than directly using 2 eigenvectors because: - It captures more structural information. - It allows the model to learn complex, non-linear mappings from the graph structure to the 2D layout.
3. Embedding Graphs into Euclidean Space
The Laplacian eigenvectors provide a way to embed or map nodes of the graph into a Euclidean space (2D or 3D), which is highly relevant for tasks like graph layout, where you want to visualize a graph or use its positional information as input to a machine learning model.
Key Steps for Graph Embedding:
- Construct the Laplacian Matrix: Start with the normalized Laplacian $L = I - D^{-\frac{1}{2}} A D^{-\frac{1}{2}}$.
- Compute Eigenvalues and Eigenvectors: Solve for the eigenvectors and eigenvalues of $L$.
- Select the Smallest Non-Trivial Eigenvectors: Ignore the first eigenvector $\mathbf{u}_1$(which corresponds to $\lambda_1 = 0$) and choose the next $k$-smallest eigenvectors (corresponding to the next smallest eigenvalues) to encode node positions.
- These smallest eigenvectors provide a smooth positional encoding of the nodes in the graph.
Example: Embedding into 2D
To embed the graph into 2D, you can ==select the two smallest non-trivial eigenvectors== $\mathbf{u}_2$and $\mathbf{u}_3$. These eigenvectors will act as the coordinates for each node in the 2D space:
- For node $i$, the coordinates would be $(\mathbf{u}_2[i], \mathbf{u}_3[i])$.
This embedding places nodes that are strongly connected close to each other in the 2D space while preserving the graph’s global structure.
4. Why Use Laplacian Positional Encoding in Graph Neural Networks (GNNs)?
The goal of a graph-based machine learning model, such as a Graph Neural Network (GNN), is to capture both local and global structure of graphs. Since GNNs are typically applied to graphs with varying sizes and connectivity, a major challenge is to design input features that are consistent in dimension across different graphs.
Laplacian Positional Encoding fixes this issue by providing fixed-dimensional node embeddings based on the graph’s structure, regardless of the number of nodes in the graph.
Eigenvectors of the Laplacian capture both local connectivity (because neighboring nodes in the graph will have similar eigenvector values) and global properties (through the spread of eigenvalues and eigenvectors).
By selecting the smallest $k$non-trivial eigenvectors, you ensure that each graph, regardless of its size, has a consistent input feature dimension, making the model more generalizable.
5. Mathematics Behind Laplacian Positional Encoding
The key equation for the graph Laplacian factorization is: $L = U \Lambda U^T$ where:
$L$is the Laplacian matrix, $U$is the matrix of eigenvectors (with each column corresponding to one eigenvector), $\Lambda$is the diagonal matrix of eigenvalues.
The process of Laplacian positional encoding involves:
- Constructing the Laplacian matrix $L$from the adjacency and degree matrices.
- Performing eigen-decomposition on $L$to find the eigenvectors and eigenvalues.
- Selecting the smallest $k$non-trivial eigenvectors (corresponding to the smallest non-zero eigenvalues) to encode the positions of the nodes.
These eigenvectors act as the positional coordinates that capture the graph’s structure in Euclidean space.
Conclusion
Laplacian eigenvectors and eigenvalues provide a powerful tool for embedding graphs into Euclidean space, which is critical for tasks like graph visualization, layout, and learning. By using Laplacian positional encoding, we can effectively represent graphs with varying numbers of nodes and structures in a fixed-dimensional space, making it highly suitable as an input feature for machine learning models, including graph neural networks.
Comments